[DATA한입] 파이썬을 활용한 경영데이터 분석(5)
(출처 :campus.hunet.co.kr/)

6.기술통계계산과 요약
1.기술통계계산
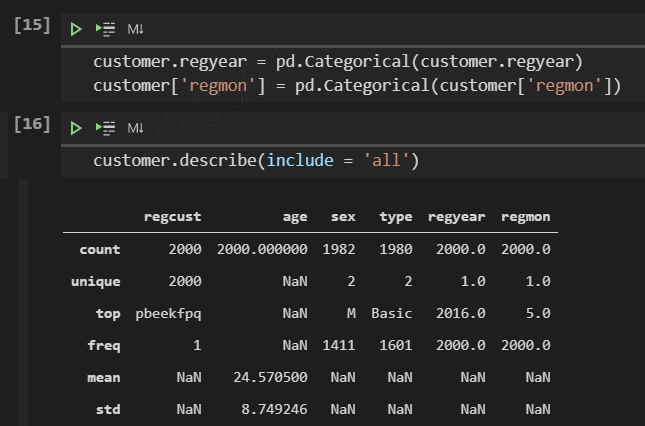
1) describe : 컬럼의 기본적인 특징을 나타내는 요약정보

2) include='all' : 모든 유형의 컬럼에 대한 기초 통계정보 확인 가능
* NA값(값이 비거나 없는 수)을 갖는 행이 있다면, count(행의 수)에서 제외하여 통계됨

3)regyear, regmon : 연도와 달은 실질적으로 범주형에 가까움
pd.Categorical() : regyear를 범주형 변수로 변경
4) 딕셔너리 변수 만들기
*pd.DataFrame() : 딕셔너리를 데이터 프레임으로 변경

5)NaN 값을 가진 행을 제거하거나 임의의 값으로 변경하기
*Customer.type.isnull() : NaN 여부 확인 가능
dropna() : NaN이 아닌 행으로 부분 집합 생성하는 함수
axis=1 : axis의 방향이 행이 아닌 '컬럼'임을 알려줌 ....NaN만 있는 '컬럼' 제거 가능
fillna() : NaN을 다른 값으로 대체 가능
2. 부분집합만들기 (슬라이싱 Slicing)
1) 특정 컬럼만 선택하는 방안
(1) Age = customer['age']
(2) customer_subset = customer[['regcust','age','type']]
2) 인덱스의 순서를 이용해 특정 행과 열을 선택하는 방안
*특정 행으로 부분집합을 생성
(1) customer_first = customer[0:100]

3) iloc 함수 : '행번호, 열번호' 형태로 행과 열 선택 가능
* customer.iloc[0:2,1:3]

4) 연속되지 않는 경우

5) 인덱스 값을 이용해 특정 행과 열을 선택하는 방안
* iloc : 행의 번호 활용 , Loc : 행의 이름 활용

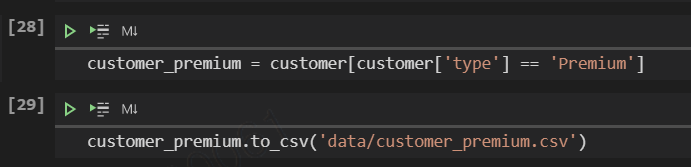
6) to_csv : 부분집합을 파일로 저장
3. 데이터 다듬기와 변형
1) 데이터 프레임에 새로운 열 추가 : 기존 데이터 프레임의 행 수와 동일한 길이의 변수인 경우

2) 기존 컬럼의 값으로 새로운 컬럼 생성

3) 데이터 프레임에서 행 및 컬럼 제거




'프로그램이야기 > Python' 카테고리의 다른 글
| [DATA한입] 파이썬을 활용한 경영데이터 분석(6) (0) | 2020.12.06 |
|---|---|
| [DATA한입] 파이썬을 활용한 경영데이터 분석(4) (0) | 2020.12.05 |
| [DATA한입] 파이썬을 활용한 경영데이터 분석(3) (0) | 2020.11.30 |
| [DATA한입] 파이썬을 활용한 경영데이터 분석(2) (0) | 2020.11.30 |
| [DATA한입] 파이썬을 활용한 경영데이터 분석(1) (2) | 2020.11.28 |



